

alibaba-1
本文的内容都是根据读者投稿的真实面试经历改编而来,首次尝试这种风格的文章,花了几天晚上才总算写完,希望对你有帮助。
本文主要涵盖下面的内容:
- 分布式商城系统:架构图讲解;
- 消息队列相关:削峰和解耦;
- Redis 相关:缓存穿透问题的解决;
- 一些基础问题:
- 网络相关:1.浏览器输入 URL 发生了什么? 2.TCP 和 UDP 区别? 3.TCP 如何保证传输可靠性?
- Java 基础:1. 既然有了字节流,为什么还要有字符流? 2.深拷贝 和 浅拷贝有啥区别呢?
下面是正文!
面试开始,坐在我前面的就是这次我的面试官吗?这发量看着根本不像程序员啊?我心里正嘀咕着,只听见面试官说:“小伙,下午好,我今天就是你的面试官,咱们开始面试吧!”。
第一面开始
面试官: 我也不用多说了,你先自我介绍一下吧,简历上有的就不要再说了哈。
我: 内心 os:"果然如我所料,就知道会让我先自我介绍一下,还好我看了 JavaGuide ,学到了一些套路。套路总结起来就是:最好准备好两份自我介绍,一份对 hr 说的,主要讲能突出自己的经历,会的编程技术一语带过;另一份对技术面试官说的,主要讲自己会的技术细节,项目经验,经历那些就一语带过。 所以,我按照这个套路准备了一个还算通用的模板,毕竟我懒嘛!不想多准备一个自我介绍,整个通用的多好!
面试官,您好!我叫小李子。大学时间我主要利用课外时间学习 Java 相关的知识。在校期间参与过一个某某系统的开发,主要负责数据库设计和后端系统开发.,期间解决了什么问题,巴拉巴拉。另外,我自己在学习过程中也参照网上的教程写过一个电商系统的网站,写这个电商网站主要是为了能让自己接触到分布式系统的开发。在学习之余,我比较喜欢通过博客整理分享自己所学知识。我现在已经是某社区的认证作者,写过一系列关于 线程池使用以及源码分析的文章深受好评。另外,我获得过省级编程比赛二等奖,我将这个获奖项目开源到 Github 还收获了 2k 的 Star 呢?
面试官: 你刚刚说参考网上的教程做了一个电商系统?你能画画这个电商系统的架构图吗?
我: 内心 os: "这可难不倒我!早知道写在简历上的项目要重视了,提前都把这个系统的架构图画了好多遍了呢!"
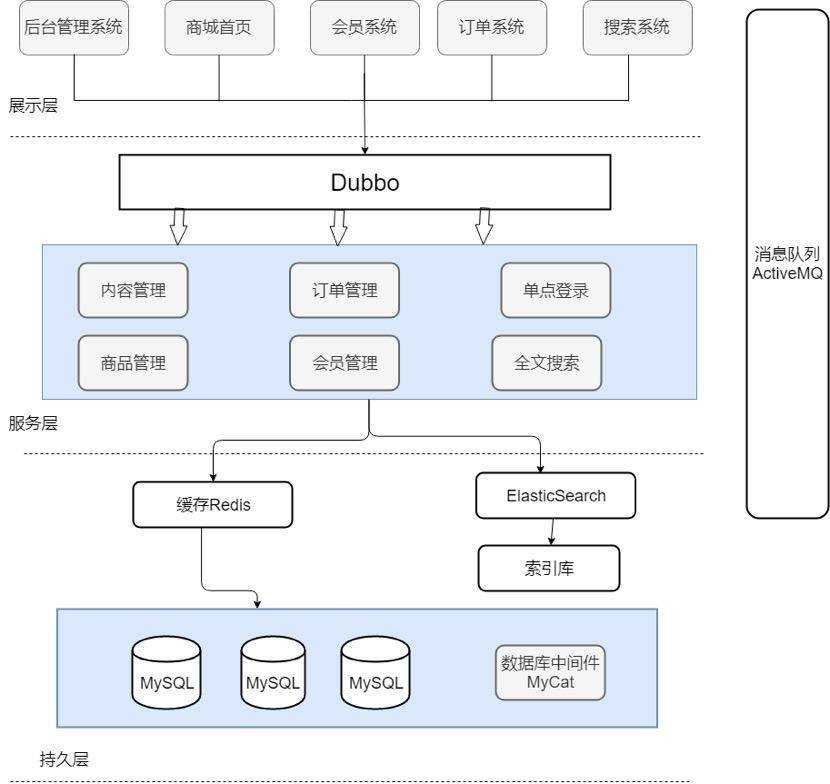
做过分布式电商系统的一定很熟悉上面的架构图(目前比较流行的是微服务架构,但是如果你有分布式开发经验也是非常加分的!)。
面试官: 简单介绍一下你做的这个系统吧!
我: 我一本正经的对着我刚刚画的商城架构图开始了满嘴造火箭的讲起来:
本系统主要分为展示层、服务层和持久层这三层。表现层顾名思义主要就是为了用来展示,比如我们的后台管理系统的页面、商城首页的页面、搜索系统的页面等等,这一层都只是作为展示,并没有提供任何服务。
展示层和服务层一般是部署在不同的机器上来提高并发量和扩展性,那么展示层和服务层怎样才能交互呢?在本系统中我们使用 Dubbo 来进行服务治理。Dubbo 是一款高性能、轻量级的开源 Java RPC 框架。Dubbo 在本系统的主要作用就是提供远程 RPC 调用。在本系统中服务层的信息通过 Dubbo 注册给 ZooKeeper,表现层通过 Dubbo 去 ZooKeeper 中获取服务的相关信息。Zookeeper 的作用仅仅是存放提供服务的服务器的地址和一些服务的相关信息,实现 RPC 远程调用功能的还是 Dubbo。如果需要引用到某个服务的时候,我们只需要在配置文件中配置相关信息就可以在代码中直接使用了,就像调用本地方法一样。假如说某个服务的使用量增加时,我们只用为这单个服务增加服务器,而不需要为整个系统添加服务。
另外,本系统的数据库使用的是常用的 MySQL,并且用到了数据库中间件 MyCat。另外,本系统还用到 redis 内存数据库来作为缓存来提高系统的反应速度。假如用户第一次访问数据库中的某些数据,这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
系统还用到了 Elasticsearch 来提供搜索功能。使用 Elasticsearch 我们可以非常方便的为我们的商城系统添加必备的搜索功能,并且使用 Elasticsearch 还能提供其它非常实用的功能,并且很容易扩展。
面试官: 我看你的系统里面还用到了消息队列,能说说为什么要用它吗?
我:
使用消息队列主要是为了:
- 减少响应所需时间和削峰。
- 降低系统耦合性(解耦/提升系统可扩展性)。
面试官: 你这说的太简单了!能不能稍微详细一点,最好能画图给我解释一下。
我: 内心 os:"都 2019 年了,大部分面试者都能对消息队列的为系统带来的这两个好处倒背如流了,如果你想走的更远就要别别人懂的更深一点!"
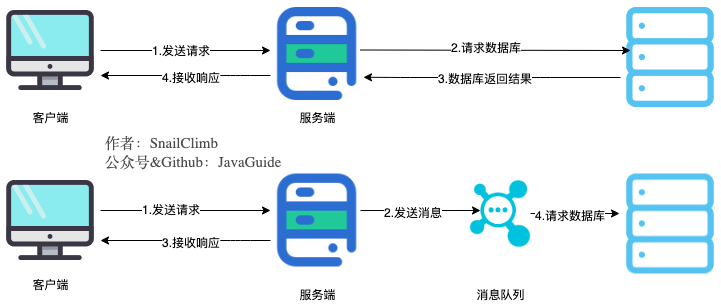
当我们不使用消息队列的时候,所有的用户的请求会直接落到服务器,然后通过数据库或者缓存响应。假如在高并发的场景下,如果没有缓存或者数据库承受不了这么大的压力的话,就会造成响应速度缓慢,甚至造成数据库宕机。但是,在使用消息队列之后,用户的请求数据发送给了消息队列之后就可以立即返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库,不过要确保消息不被重复消费还要考虑到消息丢失问题。由于消息队列服务器处理速度快于数据库,因此响应速度得到大幅改善。
文字 is too 空洞,直接上图吧!下图展示了使用消息前后系统处理用户请求的对比(ps:我自己都被我画的这个图美到了,如果你也觉得这张图好看的话麻烦来个素质三连!)。
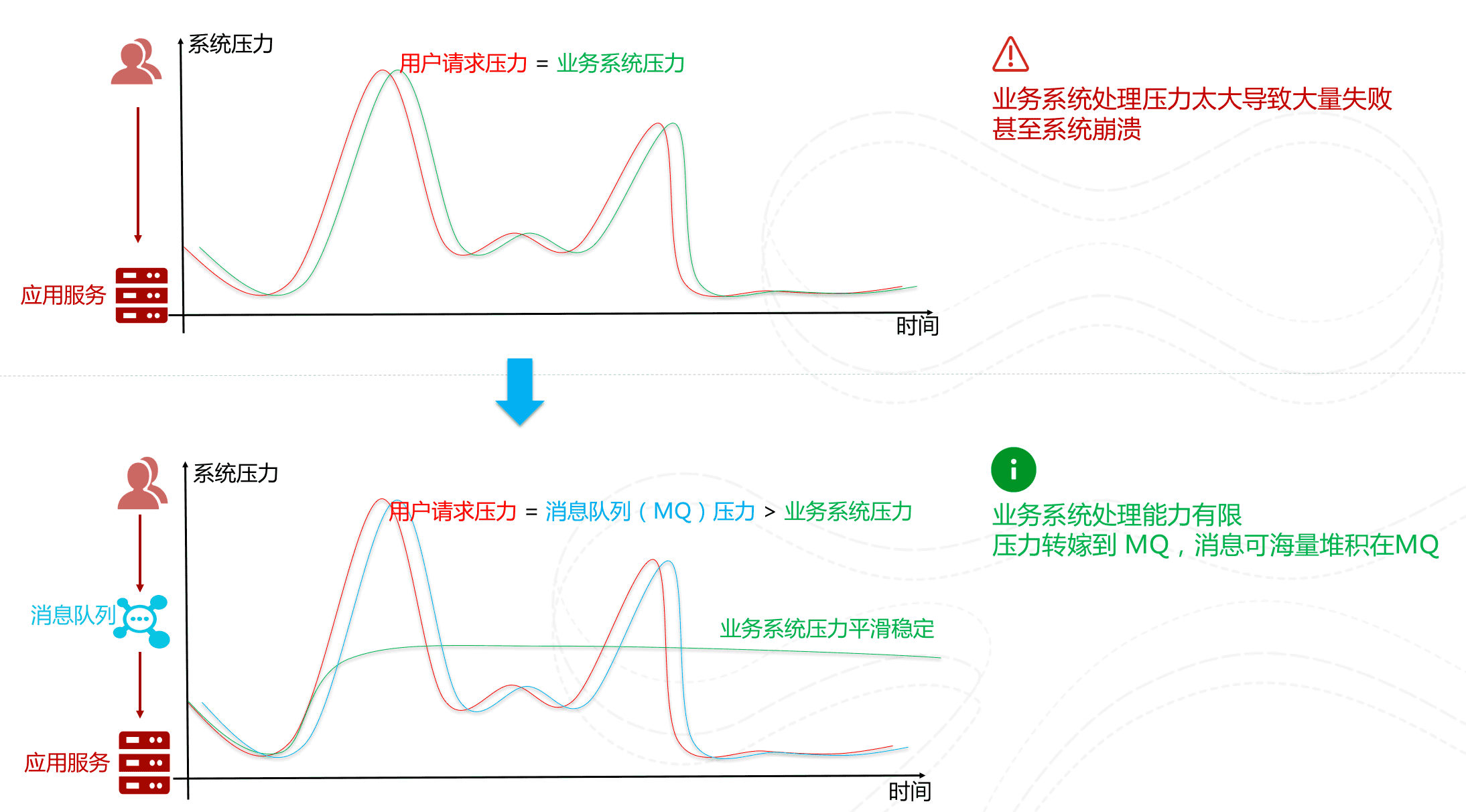
通过以上分析我们可以得出消息队列具有很好的削峰作用的功能——即通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
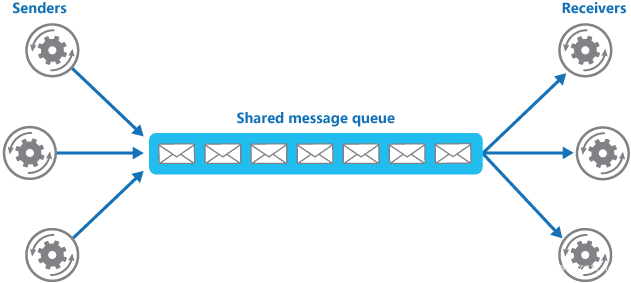
使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
面试官: 你觉得它有什么缺点吗?或者说怎么考虑用不用消息队列?
我: 内心 os: "面试官真鸡贼!这不是勾引我上钩么?还好我准备充分。"
我觉得可以从下面几个方面来说:
- 系统可用性降低: 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
- 系统复杂性提高: 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
- 一致性问题: 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
面试官:做项目的过程中遇到了什么问题吗?解决了吗?如果解决的话是如何解决的呢?
我 : 内心 os: "做的过程中好像也没有遇到什么问题啊!怎么办?怎么办?突然想到可以说我在使用 Redis 过程中遇到的问题,毕竟我对 Redis 还算熟悉嘛,把面试官往这个方向吸引,准没错。"
我在使用 Redis 对常用数据进行缓冲的过程中出现了缓存穿透问题。然后,我通过谷歌搜索相关的解决方案来解决的。
面试官: 你还知道缓存穿透啊?不错啊!来说说什么是缓存穿透以及你最后的解决办法。
我: 我先来谈谈什么是缓存穿透吧!
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
总结一下就是:
- 缓存层不命中。
- 存储层不命中,不将空结果写回缓存。
- 返回空结果给客户端。
一般 MySQL 默认的最大连接数在 150 左右,这个可以通过
show variables like '%max_connections%';命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等物理条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 的并发请求就能打死大部分数据库了。
面试官: 小伙子不错啊!还准备问你:“为什么 3000 的并发能把支持最大连接数 4000 数据库压死?”想不到你自己就提前回答了!不错!
我: 别夸了!别夸了!我再来说说我知道的一些解决办法以及我最后采用的方案吧!您帮忙看看有没有问题。
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
参数校验通过的情况还是会出现缓存穿透,我们还可以通过以下几个方案来解决这个问题:
1)缓存无效 key : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:
SET key value EX 10086。这种方式可以解决请求的 key 变化不频繁的情况,如何黑客恶意攻击,每次构建的不同的请求 key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。另外,这里多说一嘴,一般情况下我们是这样设计 key 的:
表名:列名:主键名:主键值。2)布隆过滤器: 布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
面试官: 不错不错!你还知道布隆过滤器啊!来给我谈一谈。
我: 内心 os:“如果你准备过海量数据处理的面试题,你一定对:“如何确定一个数字是否在于包含大量数字的数字集中(数字集很大,5 亿以上!)?”这个题目很了解了!解决这道题目就要用到布隆过滤器。”
布隆过滤器在针对海量数据去重或者验证数据合法性的时候非常有用。布隆过滤器的本质实际上是 “位(bit)数组”,也就是说每一个存入布隆过滤器的数据都只占一位。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
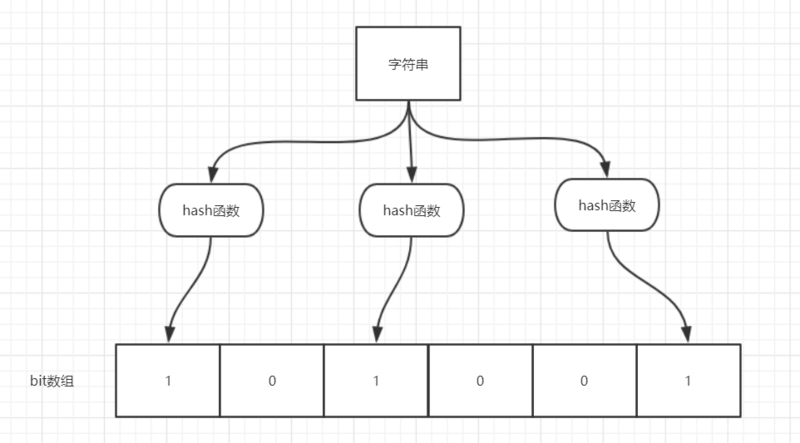
举个简单的例子:
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
面试官: 看来你对布隆过滤器了解的还挺不错的嘛!那你快说说你最后是怎么利用它来解决缓存穿透的。
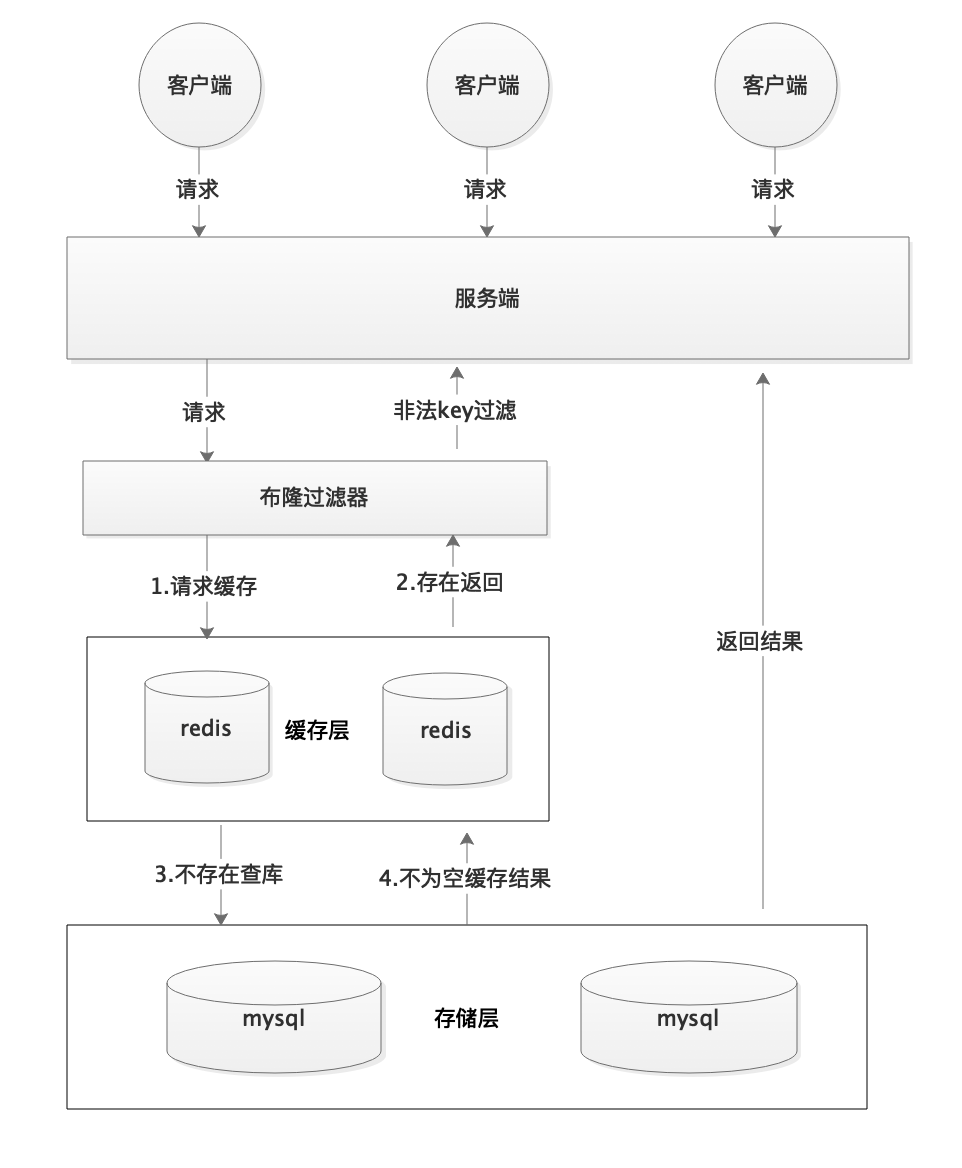
我: 知道了布隆过滤器的原理就之后就很容易做了。我是利用 Redis 布隆过滤器来做的。我把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
更多关于布隆过滤器的内容可以看我的这篇原创:《不了解布隆过滤器?一文给你整的明明白白!》 ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
面试官: 好了好了。项目就暂时问到这里吧!下面有一些比较基础的问题我简单地问一下你。内心 os: 难不成这家伙满口高并发,连最基础的东西都不会吧!
我: 好的好的!没问题!
面试官: 浏览器输入 URL 发生了什么?
我: 内心 os:“很常问的一个问题,建议拿小本本记好了!另外,百度好像最喜欢问这个问题,去百度面试可要提前备好这道题的功课哦!相似问题:打开一个网页,整个过程会使用哪些协议?”。
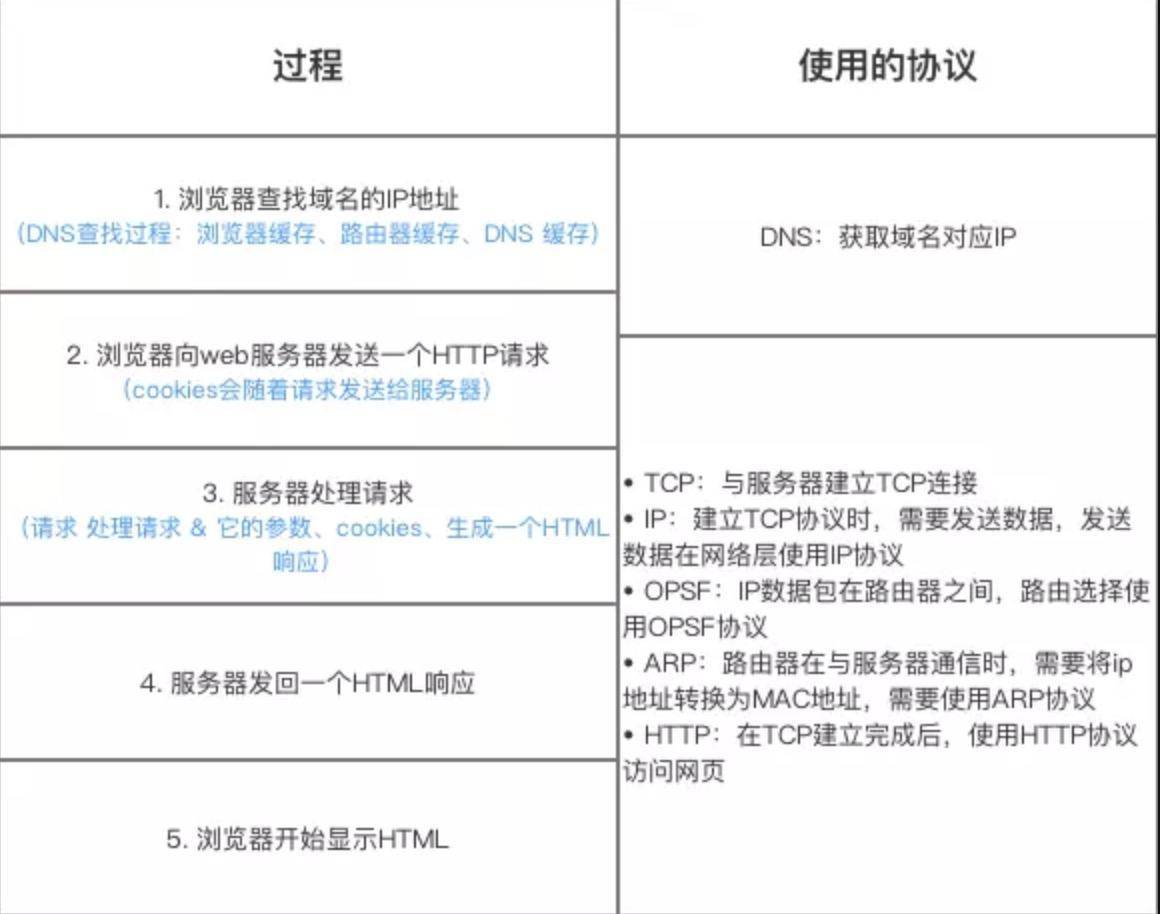
图解(图片来源:《图解 HTTP》):
总体来说分为以下几个过程:
- DNS 解析
- TCP 连接
- 发送 HTTP 请求
- 服务器处理请求并返回 HTTP 报文
- 浏览器解析渲染页面
- 连接结束
具体可以参考下面这篇文章:
面试官: TCP 和 UDP 区别?
我:
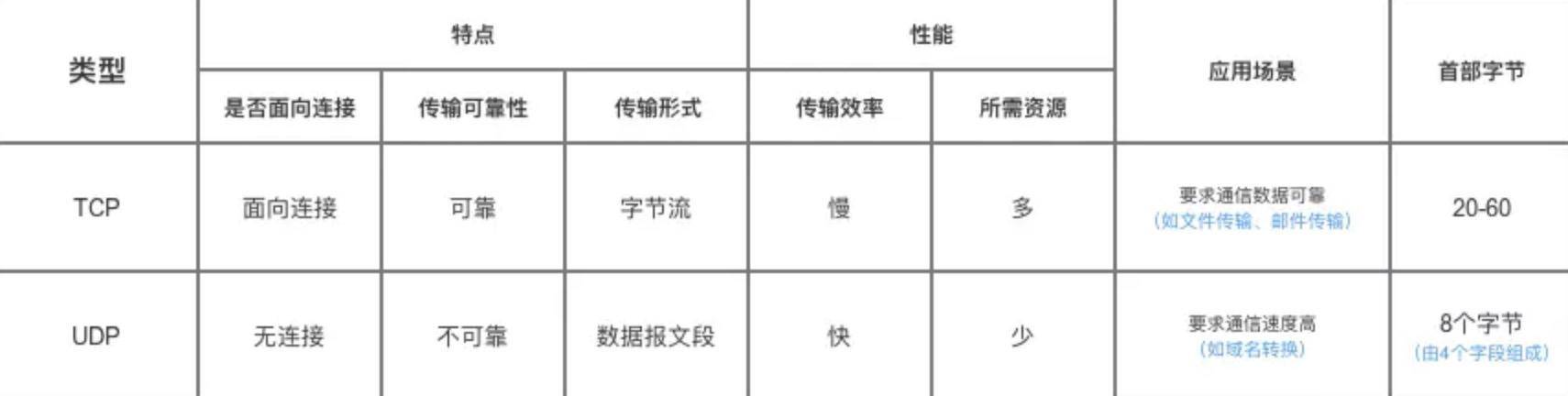
UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
面试官: TCP 如何保证传输可靠性?
我:
- 应用数据被分割成 TCP 认为最适合发送的数据块。
- TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
- 校验和: TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
- TCP 的接收端会丢弃重复的数据。
- 流量控制: TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
- 拥塞控制: 当网络拥塞时,减少数据的发送。
- ARQ 协议: 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
- 超时重传: 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
面试官: 我再来问你一些 Java 基础的问题吧!小伙子。
我: 好的。(内心 os:“你尽管来!”)
面试官: 既然有了字节流,为什么还要有字符流?
我:内心 os :“问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?”
字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
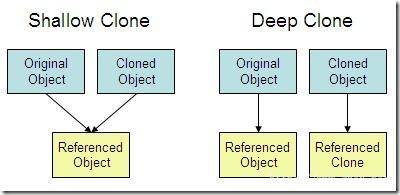
面试官:深拷贝 和 浅拷贝有啥区别呢?
我:
- 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
- 深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
面试官: 好的!面试结束。小伙子可以的!回家等通知吧!
我: 好的好的!辛苦您了!












