Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html
网站日志分析项目案例(三)统计分析:http://www.cnblogs.com/edisonchou/p/4464349.html
一、数据情况分析
1.1 数据情况回顾
该论坛数据有两部分:
(1)历史数据约56GB,统计到2012-05-29。这也说明,在2012-05-29之前,日志文件都在一个文件里边,采用了追加写入的方式。
(2)自2013-05-30起,每天生成一个数据文件,约150MB左右。这也说明,从2013-05-30之后,日志文件不再是在一个文件里边。
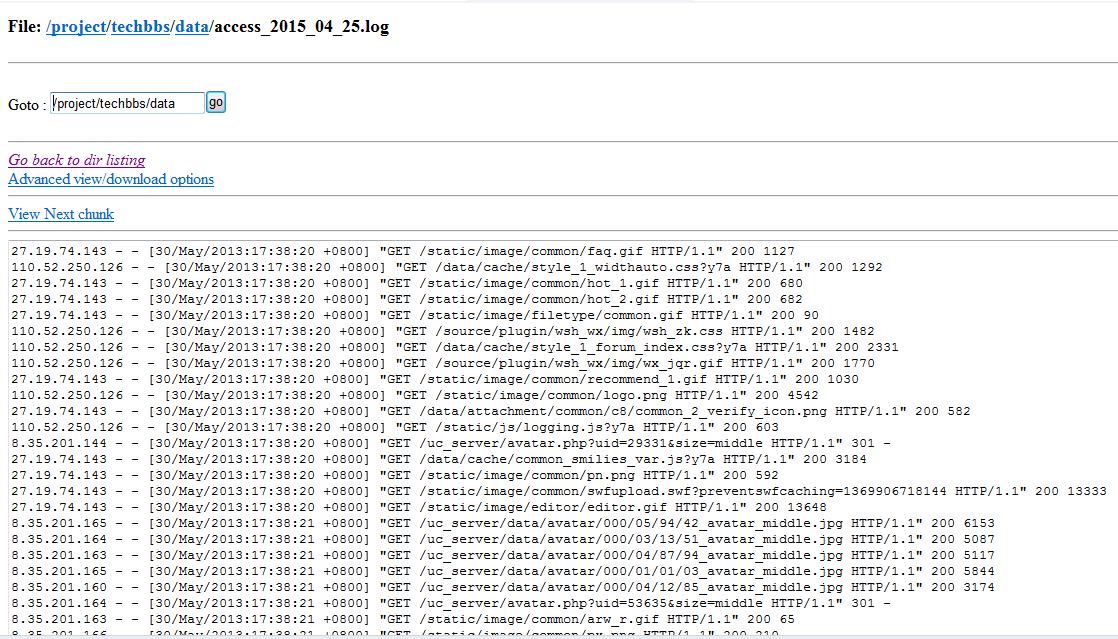
图1展示了该日志数据的记录格式,其中每行记录有5部分组成:访问者IP、访问时间、访问资源、访问状态(HTTP状态码)、本次访问流量。

图1 日志记录数据格式
本次使用数据来自于两个2013年的日志文件,分别为access_2013_05_30.log与access_2013_05_31.log,下载地址为:http://pan.baidu.com/s/1pJE7XR9
1.2 要清理的数据
(1)根据前一篇的关键指标的分析,我们所要统计分析的均不涉及到访问状态(HTTP状态码)以及本次访问的流量,于是我们首先可以将这两项记录清理掉;
(2)根据日志记录的数据格式,我们需要将日期格式转换为平常所见的普通格式如20150426这种,于是我们可以写一个类将日志记录的日期进行转换;
(3)由于静态资源的访问请求对我们的数据分析没有意义,于是我们可以将"GET /staticsource/"开头的访问记录过滤掉,又因为GET和POST字符串对我们也没有意义,因此也可以将其省略掉;
二、数据清洗过程
2.1 定期上传日志至HDFS
首先,把日志数据上传到HDFS中进行处理,可以分为以下几种情况:
(1)如果是日志服务器数据较小、压力较小,可以直接使用shell命令把数据上传到HDFS中;
(2)如果是日志服务器数据较大、压力较大,使用NFS在另一台服务器上上传数据;
(3)如果日志服务器非常多、数据量大,使用flume进行数据处理;
这里我们的实验数据文件较小,因此直接采用第一种Shell命令方式。又因为日志文件时每天产生的,因此需要设置一个定时任务,在第二天的1点钟自动将前一天产生的log文件上传到HDFS的指定目录中。所以,我们通过shell脚本结合crontab创建一个定时任务techbbs_core.sh,内容如下:
#!/bin/sh
#step1.get yesterday format string
yesterday=$(date --date='1 days ago' +%Y_%m_%d)
#step2.upload logs to hdfs
hadoop fs -put /usr/local/files/apache_logs/access_${yesterday}.log /project/techbbs/data
结合crontab设置为每天1点钟自动执行的定期任务:crontab -e,内容如下(其中1代表每天1:00,techbbs_core.sh为要执行的脚本文件):
* 1 * * * techbbs_core.sh
验证方式:通过命令 crontab -l 可以查看已经设置的定时任务
2.2 编写MapReduce程序清理日志
(1)编写日志解析类对每行记录的五个组成部分进行单独的解析
static class LogParser { public static final SimpleDateFormat FORMAT = new SimpleDateFormat( "d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); public static final SimpleDateFormat dateformat1 = new SimpleDateFormat( "yyyyMMddHHmmss");/** * 解析英文时间字符串 * * @param string * @return * @throws ParseException */ private Date parseDateFormat(String string) { Date parse = null; try { parse = FORMAT.parse(string); } catch (ParseException e) { e.printStackTrace(); } return parse; } /** * 解析日志的行记录 * * @param line * @return 数组含有5个元素,分别是ip、时间、url、状态、流量 */ public String[] parse(String line) { String ip = parseIP(line); String time = parseTime(line); String url = parseURL(line); String status = parseStatus(line); String traffic = parseTraffic(line); return new String[] { ip, time, url, status, traffic }; } private String parseTraffic(String line) { final String trim = line.substring(line.lastIndexOf("\"") + 1) .trim(); String traffic = trim.split(" ")[1]; return traffic; } private String parseStatus(String line) { final String trim = line.substring(line.lastIndexOf("\"") + 1) .trim(); String status = trim.split(" ")[0]; return status; } private String parseURL(String line) { final int first = line.indexOf("\""); final int last = line.lastIndexOf("\""); String url = line.substring(first + 1, last); return url; } private String parseTime(String line) { final int first = line.indexOf("["); final int last = line.indexOf("+0800]"); String time = line.substring(first + 1, last).trim(); Date date = parseDateFormat(time); return dateformat1.format(date); } private String parseIP(String line) { String ip = line.split("- -")[0].trim(); return ip; } }
(2)编写MapReduce程序对指定日志文件的所有记录进行过滤
Mapper类:
static class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text> { LogParser logParser = new LogParser(); Text outputValue = new Text(); protected void map( LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, LongWritable, Text>.Context context) throws java.io.IOException, InterruptedException { final String[] parsed = logParser.parse(value.toString()); // step1.过滤掉静态资源访问请求 if (parsed[2].startsWith("GET /static/") || parsed[2].startsWith("GET /uc_server")) { return; } // step2.过滤掉开头的指定字符串 if (parsed[2].startsWith("GET /")) { parsed[2] = parsed[2].substring("GET /".length()); } else if (parsed[2].startsWith("POST /")) { parsed[2] = parsed[2].substring("POST /".length()); } // step3.过滤掉结尾的特定字符串 if (parsed[2].endsWith(" HTTP/1.1")) { parsed[2] = parsed[2].substring(0, parsed[2].length() - " HTTP/1.1".length()); } // step4.只写入前三个记录类型项 outputValue.set(parsed[0] + "\t" + parsed[1] + "\t" + parsed[2]); context.write(key, outputValue); } }
Reducer类:
static class MyReducer extends Reducer<LongWritable, Text, Text, NullWritable> { protected void reduce( LongWritable k2, java.lang.Iterable<Text> v2s, org.apache.hadoop.mapreduce.Reducer<LongWritable, Text, Text, NullWritable>.Context context) throws java.io.IOException, InterruptedException { for (Text v2 : v2s) { context.write(v2, NullWritable.get()); } }; }
(3)LogCleanJob.java的完整示例代码


package techbbs; import java.net.URI; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Locale; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class LogCleanJob extends Configured implements Tool { public static void main(String[] args) { Configuration conf = new Configuration(); try { int res = ToolRunner.run(conf, new LogCleanJob(), args); System.exit(res); } catch (Exception e) { e.printStackTrace(); } } @Override public int run(String[] args) throws Exception { final Job job = new Job(new Configuration(), LogCleanJob.class.getSimpleName()); // 设置为可以打包运行 job.setJarByClass(LogCleanJob.class); FileInputFormat.setInputPaths(job, args[0]); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 清理已存在的输出文件 FileSystem fs = FileSystem.get(new URI(args[0]), getConf()); Path outPath = new Path(args[1]); if (fs.exists(outPath)) { fs.delete(outPath, true); } boolean success = job.waitForCompletion(true); if(success){ System.out.println("Clean process success!"); } else{ System.out.println("Clean process failed!"); } return 0; } static class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text> { LogParser logParser = new LogParser(); Text outputValue = new Text(); protected void map( LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, LongWritable, Text>.Context context) throws java.io.IOException, InterruptedException { final String[] parsed = logParser.parse(value.toString()); // step1.过滤掉静态资源访问请求 if (parsed[2].startsWith("GET /static/") || parsed[2].startsWith("GET /uc_server")) { return; } // step2.过滤掉开头的指定字符串 if (parsed[2].startsWith("GET /")) { parsed[2] = parsed[2].substring("GET /".length()); } else if (parsed[2].startsWith("POST /")) { parsed[2] = parsed[2].substring("POST /".length()); } // step3.过滤掉结尾的特定字符串 if (parsed[2].endsWith(" HTTP/1.1")) { parsed[2] = parsed[2].substring(0, parsed[2].length() - " HTTP/1.1".length()); } // step4.只写入前三个记录类型项 outputValue.set(parsed[0] + "\t" + parsed[1] + "\t" + parsed[2]); context.write(key, outputValue); } } static class MyReducer extends Reducer<LongWritable, Text, Text, NullWritable> { protected void reduce( LongWritable k2, java.lang.Iterable<Text> v2s, org.apache.hadoop.mapreduce.Reducer<LongWritable, Text, Text, NullWritable>.Context context) throws java.io.IOException, InterruptedException { for (Text v2 : v2s) { context.write(v2, NullWritable.get()); } }; } /* * 日志解析类 */ static class LogParser { public static final SimpleDateFormat FORMAT = new SimpleDateFormat( "d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); public static final SimpleDateFormat dateformat1 = new SimpleDateFormat( "yyyyMMddHHmmss"); public static void main(String[] args) throws ParseException { final String S1 = "27.19.74.143 - - [30/May/2013:17:38:20 +0800] \"GET /static/image/common/faq.gif HTTP/1.1\" 200 1127"; LogParser parser = new LogParser(); final String[] array = parser.parse(S1); System.out.println("样例数据: " + S1); System.out.format( "解析结果: ip=%s, time=%s, url=%s, status=%s, traffic=%s", array[0], array[1], array[2], array[3], array[4]); } /** * 解析英文时间字符串 * * @param string * @return * @throws ParseException */ private Date parseDateFormat(String string) { Date parse = null; try { parse = FORMAT.parse(string); } catch (ParseException e) { e.printStackTrace(); } return parse; } /** * 解析日志的行记录 * * @param line * @return 数组含有5个元素,分别是ip、时间、url、状态、流量 */ public String[] parse(String line) { String ip = parseIP(line); String time = parseTime(line); String url = parseURL(line); String status = parseStatus(line); String traffic = parseTraffic(line); return new String[] { ip, time, url, status, traffic }; } private String parseTraffic(String line) { final String trim = line.substring(line.lastIndexOf("\"") + 1) .trim(); String traffic = trim.split(" ")[1]; return traffic; } private String parseStatus(String line) { final String trim = line.substring(line.lastIndexOf("\"") + 1) .trim(); String status = trim.split(" ")[0]; return status; } private String parseURL(String line) { final int first = line.indexOf("\""); final int last = line.lastIndexOf("\""); String url = line.substring(first + 1, last); return url; } private String parseTime(String line) { final int first = line.indexOf("["); final int last = line.indexOf("+0800]"); String time = line.substring(first + 1, last).trim(); Date date = parseDateFormat(time); return dateformat1.format(date); } private String parseIP(String line) { String ip = line.split("- -")[0].trim(); return ip; } } }
(4)导出jar包,并将其上传至Linux服务器指定目录中
2.3 定期清理日志至HDFS
这里我们改写刚刚的定时任务脚本,将自动执行清理的MapReduce程序加入脚本中,内容如下:
#!/bin/sh
#step1.get yesterday format string
yesterday=$(date --date='1 days ago' +%Y_%m_%d)
#step2.upload logs to hdfs
hadoop fs -put /usr/local/files/apache_logs/access_${yesterday}.log /project/techbbs/data
#step3.clean log data
hadoop jar /usr/local/files/apache_logs/mycleaner.jar /project/techbbs/data/access_${yesterday}.log /project/techbbs/cleaned/${yesterday}
这段脚本的意思就在于每天1点将日志文件上传到HDFS后,执行数据清理程序对已存入HDFS的日志文件进行过滤,并将过滤后的数据存入cleaned目录下。
2.4 定时任务测试
(1)因为两个日志文件是2013年的,因此这里将其名称改为2015年当天以及前一天的,以便这里能够测试通过。
(2)执行命令:techbbs_core.sh 2014_04_26
控制台的输出信息如下所示,可以看到过滤后的记录减少了很多:
15/04/26 04:27:20 INFO input.FileInputFormat: Total input paths to process : 1
15/04/26 04:27:20 INFO util.NativeCodeLoader: Loaded the native-hadoop library
15/04/26 04:27:20 WARN snappy.LoadSnappy: Snappy native library not loaded
15/04/26 04:27:22 INFO mapred.JobClient: Running job: job_201504260249_0002
15/04/26 04:27:23 INFO mapred.JobClient: map 0% reduce 0%
15/04/26 04:28:01 INFO mapred.JobClient: map 29% reduce 0%
15/04/26 04:28:07 INFO mapred.JobClient: map 42% reduce 0%
15/04/26 04:28:10 INFO mapred.JobClient: map 57% reduce 0%
15/04/26 04:28:13 INFO mapred.JobClient: map 74% reduce 0%
15/04/26 04:28:16 INFO mapred.JobClient: map 89% reduce 0%
15/04/26 04:28:19 INFO mapred.JobClient: map 100% reduce 0%
15/04/26 04:28:49 INFO mapred.JobClient: map 100% reduce 100%
15/04/26 04:28:50 INFO mapred.JobClient: Job complete: job_201504260249_0002
15/04/26 04:28:50 INFO mapred.JobClient: Counters: 29
15/04/26 04:28:50 INFO mapred.JobClient: Job Counters
15/04/26 04:28:50 INFO mapred.JobClient: Launched reduce tasks=1
15/04/26 04:28:50 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=58296
15/04/26 04:28:50 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
15/04/26 04:28:50 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
15/04/26 04:28:50 INFO mapred.JobClient: Launched map tasks=1
15/04/26 04:28:50 INFO mapred.JobClient: Data-local map tasks=1
15/04/26 04:28:50 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=25238
15/04/26 04:28:50 INFO mapred.JobClient: File Output Format Counters
15/04/26 04:28:50 INFO mapred.JobClient: Bytes Written=12794925
15/04/26 04:28:50 INFO mapred.JobClient: FileSystemCounters
15/04/26 04:28:50 INFO mapred.JobClient: FILE_BYTES_READ=14503530
15/04/26 04:28:50 INFO mapred.JobClient: HDFS_BYTES_READ=61084325
15/04/26 04:28:50 INFO mapred.JobClient: FILE_BYTES_WRITTEN=29111500
15/04/26 04:28:50 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=12794925
15/04/26 04:28:50 INFO mapred.JobClient: File Input Format Counters
15/04/26 04:28:50 INFO mapred.JobClient: Bytes Read=61084192
15/04/26 04:28:50 INFO mapred.JobClient: Map-Reduce Framework
15/04/26 04:28:50 INFO mapred.JobClient: Map output materialized bytes=14503530
15/04/26 04:28:50 INFO mapred.JobClient: Map input records=548160
15/04/26 04:28:50 INFO mapred.JobClient: Reduce shuffle bytes=14503530
15/04/26 04:28:50 INFO mapred.JobClient: Spilled Records=339714
15/04/26 04:28:50 INFO mapred.JobClient: Map output bytes=14158741
15/04/26 04:28:50 INFO mapred.JobClient: CPU time spent (ms)=21200
15/04/26 04:28:50 INFO mapred.JobClient: Total committed heap usage (bytes)=229003264
15/04/26 04:28:50 INFO mapred.JobClient: Combine input records=0
15/04/26 04:28:50 INFO mapred.JobClient: SPLIT_RAW_BYTES=133
15/04/26 04:28:50 INFO mapred.JobClient: Reduce input records=169857
15/04/26 04:28:50 INFO mapred.JobClient: Reduce input groups=169857
15/04/26 04:28:50 INFO mapred.JobClient: Combine output records=0
15/04/26 04:28:50 INFO mapred.JobClient: Physical memory (bytes) snapshot=154001408
15/04/26 04:28:50 INFO mapred.JobClient: Reduce output records=169857
15/04/26 04:28:50 INFO mapred.JobClient: Virtual memory (bytes) snapshot=689442816
15/04/26 04:28:50 INFO mapred.JobClient: Map output records=169857
Clean process success!
(3)通过Web接口查看HDFS中的日志数据:
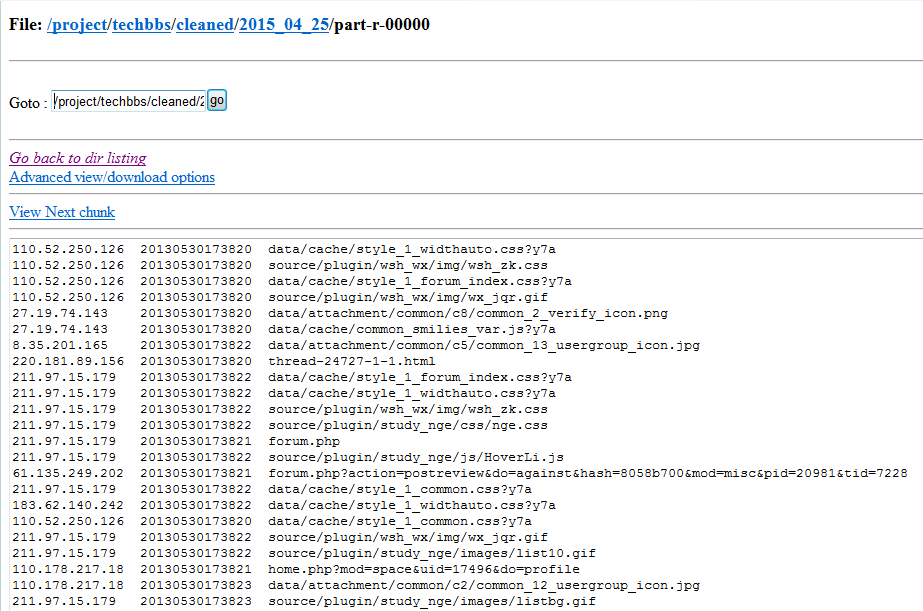
存入的未过滤的日志数据:/project/techbbs/data/
存入的已过滤的日志数据:/project/techbbs/cleaned/