

Hadoop学习笔记—4.初识MapReduce
一、神马是高大上的MapReduce
MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。但对许多开发者来说,自己完完全全实现一个并行计算程序难度太大,而MapReduce就是一种简化并行计算的编程模型,它使得那些没有多有多少并行计算经验的开发人员也可以开发并行应用程序。这也就是MapReduce的价值所在,通过简化编程模型,降低了开发并行应用的入门门槛。
1.1 MapReduce是什么
Hadoop MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。这个定义里面有着这些关键词,一是软件框架,二是并行处理,三是可靠且容错,四是大规模集群,五是海量数据集。
因此,对于MapReduce,可以简洁地认为,它是一个软件框架,海量数据是它的“菜”,它在大规模集群上以一种可靠且容错的方式并行地“烹饪这道菜”。
1.2 MapReduce做什么
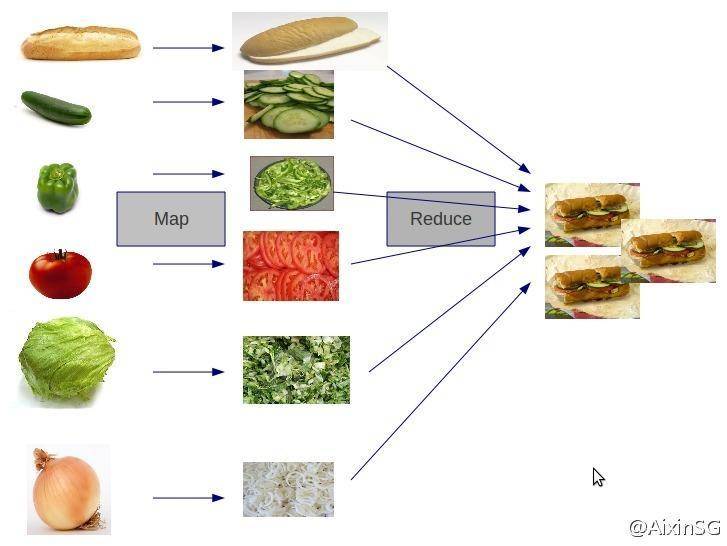
简单地讲,MapReduce可以做大数据处理。所谓大数据处理,即以价值为导向,对大数据加工、挖掘和优化等各种处理。
MapReduce擅长处理大数据,它为什么具有这种能力呢?这可由MapReduce的设计思想发觉。MapReduce的思想就是“分而治之”。
(1)Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
(2)Reducer负责对map阶段的结果进行汇总。至于需要多少个Reducer,用户可以根据具体问题,通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
一个比较形象的语言解释MapReduce:
We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That’s map. The more people we get, the faster it goes.
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
Now we get together and add our individual counts. That’s reduce.
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
1.3 MapReduce工作机制
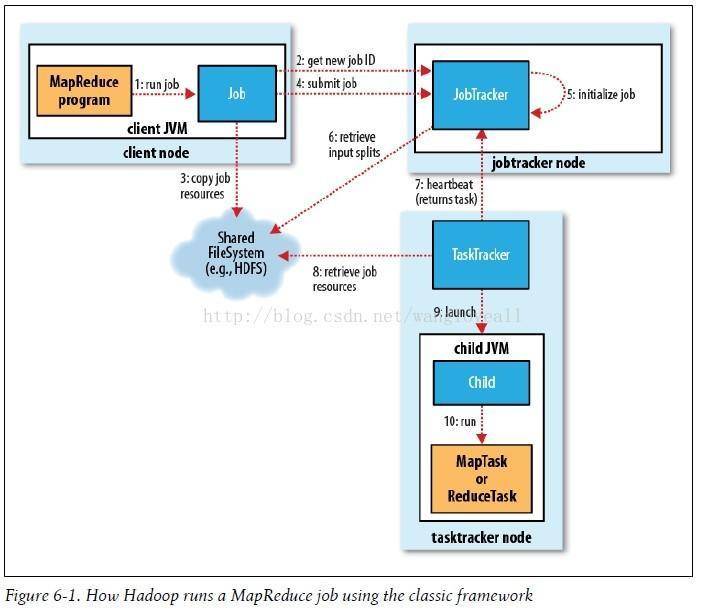
MapReduce的整个工作过程如上图所示,它包含如下4个独立的实体:
实体一:客户端,用来提交MapReduce作业。
实体二:JobTracker,用来协调作业的运行。
实体三:TaskTracker,用来处理作业划分后的任务。
实体四:HDFS,用来在其它实体间共享作业文件。
通过审阅MapReduce的工作流程图,可以看出MapReduce整个工作过程有序地包含如下工作环节:
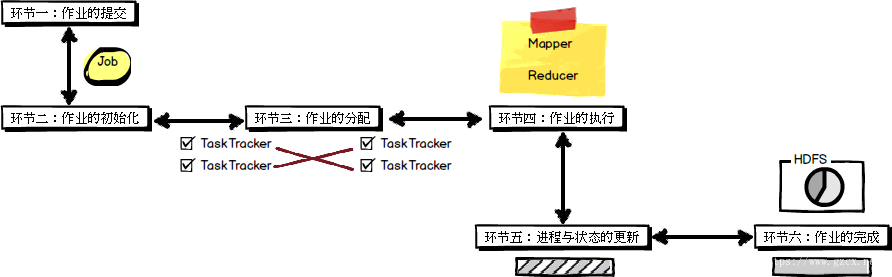
二、Hadoop中的MapReduce框架
在Hadoop中,一个MapReduce作业通常会把输入的数据集切分为若干独立的数据块,由Map任务以完全并行的方式去处理它们。框架会对Map的输出先进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中,整个框架负责任务的调度和监控,以及重新执行已经关闭的任务。
通常,MapReduce框架和分布式文件系统是运行在一组相同的节点上,也就是说,计算节点和存储节点通常都是在一起的。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使得整个集群的网络带宽被非常高效地利用。
2.1 MapReduce框架的组成
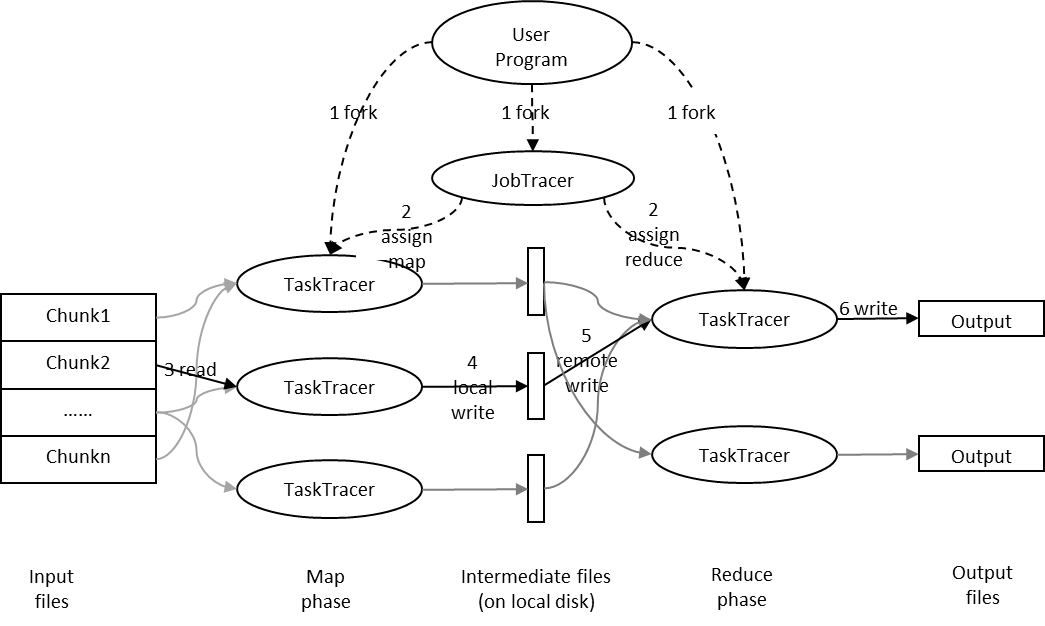
(1)JobTracker
JobTracker负责调度构成一个作业的所有任务,这些任务分布在不同的TaskTracker上(由上图的JobTracker可以看到2 assign map 和 3 assign reduce)。你可以将其理解为公司的项目经理,项目经理接受项目需求,并划分具体的任务给下面的开发工程师。
(2)TaskTracker
TaskTracker负责执行由JobTracker指派的任务,这里我们就可以将其理解为开发工程师,完成项目经理安排的开发任务即可。
2.2 MapReduce的输入输出
MapReduce框架运转在<key,value>键值对上,也就是说,框架把作业的输入看成是一组<key,value>键值对,同样也产生一组<key,value>键值对作为作业的输出,这两组键值对有可能是不同的。
一个MapReduce作业的输入和输出类型如下图所示:可以看出在整个流程中,会有三组<key,value>键值对类型的存在。

2.3 MapReduce的处理流程
这里以WordCount单词计数为例,介绍map和reduce两个阶段需要进行哪些处理。单词计数主要完成的功能是:统计一系列文本文件中每个单词出现的次数,如图所示:
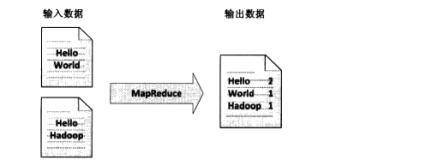
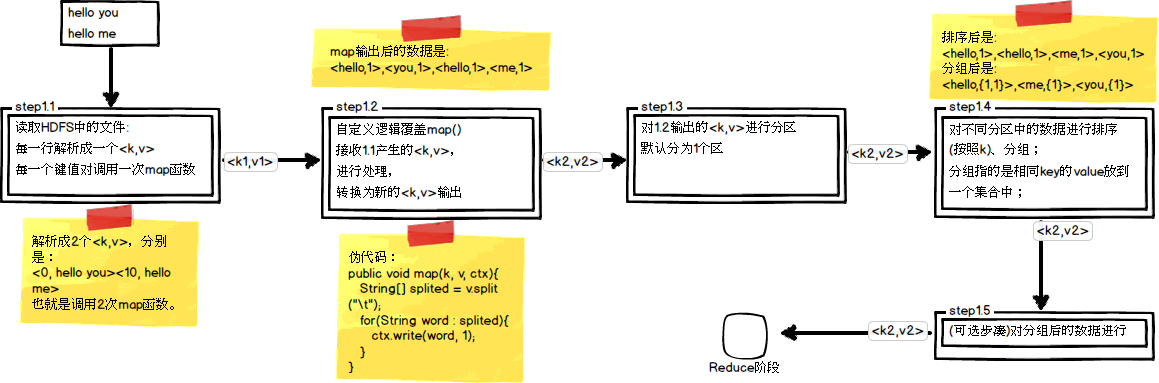
(1)map任务处理
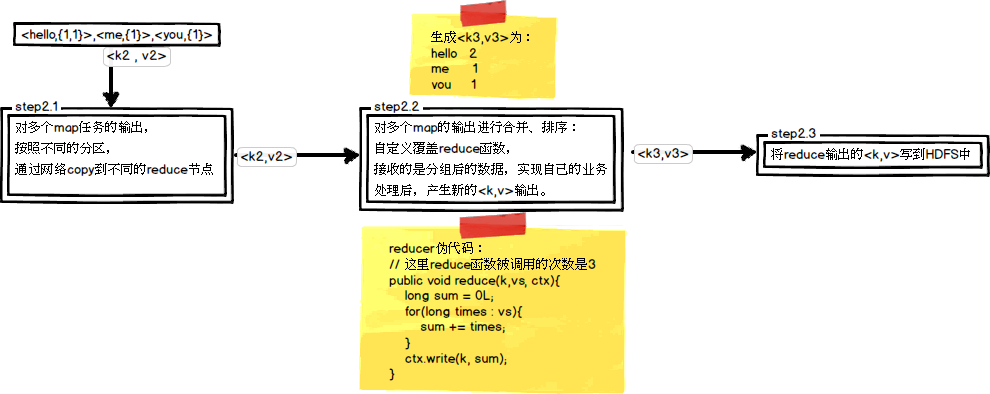
(2)reduce任务处理
三、第一个MapReduce程序:WordCount
WordCount单词计数是最简单也是最能体现MapReduce思想的程序之一,该程序完整的代码可以在Hadoop安装包的src/examples目录下找到。
WordCount单词计数主要完成的功能是:统计一系列文本文件中每个单词出现的次数;
3.1 初始化一个words.txt文件并上传HDFS
首先在Linux中通过Vim编辑一个简单的words.txt,其内容很简单如下所示:
Hello Edison Chou
Hello Hadoop RPC
Hello Wncud Chou
Hello Hadoop MapReduce
Hello Dick Gu
通过Shell命令将其上传到一个指定目录中,这里指定为:/testdir/input
3.2 自定义Map函数
在Hadoop 中, map 函数位于内置类org.apache.hadoop.mapreduce.Mapper<KEYIN,VALUEIN, KEYOUT, VALUEOUT>中,reduce 函数位于内置类org.apache.hadoop. mapreduce.Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>中。
我们要做的就是覆盖map 函数和reduce 函数,首先我们来覆盖map函数:继承Mapper类并重写map方法
/** * @author Edison Chou * @version 1.0 * @param KEYIN * →k1 表示每一行的起始位置(偏移量offset) * @param VALUEIN * →v1 表示每一行的文本内容 * @param KEYOUT * →k2 表示每一行中的每个单词 * @param VALUEOUT * →v2 表示每一行中的每个单词的出现次数,固定值为1 */ public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException { String[] spilted = value.toString().split(" "); for (String word : spilted) { context.write(new Text(word), new LongWritable(1L)); } }; }
Mapper 类,有四个泛型,分别是KEYIN、VALUEIN、KEYOUT、VALUEOUT,前面两个KEYIN、VALUEIN 指的是map 函数输入的参数key、value 的类型;后面两个KEYOUT、VALUEOUT 指的是map 函数输出的key、value 的类型;
从代码中可以看出,在Mapper类和Reducer类中都使用了Hadoop自带的基本数据类型,例如String对应Text,long对应LongWritable,int对应IntWritable。这是因为HDFS涉及到序列化的问题,Hadoop的基本数据类型都实现了一个Writable接口,而实现了这个接口的类型都支持序列化。
这里的map函数中通过空格符号来分割文本内容,并对其进行记录;
3.3 自定义Reduce函数
现在我们来覆盖reduce函数:继承Reducer类并重写reduce方法
/** * @author Edison Chou * @version 1.0 * @param KEYIN * →k2 表示每一行中的每个单词 * @param VALUEIN * →v2 表示每一行中的每个单词的出现次数,固定值为1 * @param KEYOUT * →k3 表示每一行中的每个单词 * @param VALUEOUT * →v3 表示每一行中的每个单词的出现次数之和 */ public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { protected void reduce(Text key, java.lang.Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException { long count = 0L; for (LongWritable value : values) { count += value.get(); } context.write(key, new LongWritable(count)); }; }
Reducer 类,也有四个泛型,同理,分别指的是reduce 函数输入的key、value类型(这里输入的key、value类型通常和map的输出key、value类型保持一致)和输出的key、value 类型。
这里的reduce函数主要是将传入的<k2,v2>进行最后的合并统计,形成最后的统计结果。
3.4 设置Main函数
(1)设定输入目录,当然也可以作为参数传入
public static final String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/words.txt";
(2)设定输出目录(输出目录需要是空目录),当然也可以作为参数传入
public static final String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/wordcount";
(3)Main函数的主要代码
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // 0.0:首先删除输出路径的已有生成文件 FileSystem fs = FileSystem.get(new URI(INPUT_PATH), conf); Path outPath = new Path(OUTPUT_PATH); if (fs.exists(outPath)) { fs.delete(outPath, true); } Job job = new Job(conf, "WordCount"); job.setJarByClass(MyWordCountJob.class); // 1.0:指定输入目录 FileInputFormat.setInputPaths(job, new Path(INPUT_PATH)); // 1.1:指定对输入数据进行格式化处理的类(可以省略) job.setInputFormatClass(TextInputFormat.class); // 1.2:指定自定义的Mapper类 job.setMapperClass(MyMapper.class); // 1.3:指定map输出的<K,V>类型(如果<k3,v3>的类型与<k2,v2>的类型一致则可以省略) job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 1.4:分区(可以省略) job.setPartitionerClass(HashPartitioner.class); // 1.5:设置要运行的Reducer的数量(可以省略) job.setNumReduceTasks(1); // 1.6:指定自定义的Reducer类 job.setReducerClass(MyReducer.class); // 1.7:指定reduce输出的<K,V>类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 1.8:指定输出目录 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); // 1.9:指定对输出数据进行格式化处理的类(可以省略) job.setOutputFormatClass(TextOutputFormat.class); // 2.0:提交作业 boolean success = job.waitForCompletion(true); if (success) { System.out.println("Success"); System.exit(0); } else { System.out.println("Failed"); System.exit(1); } }
在Main函数中,主要做了三件事:一是指定输入、输出目录;二是指定自定义的Mapper类和Reducer类;三是提交作业;匆匆看下来,代码有点多,但有些其实是可以省略的。
(4)完整代码如下所示


package mapreduce; import java.io.FileInputStream; import java.io.IOException; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; public class MyWordCountJob { /** * @author Edison Chou * @version 1.0 * @param KEYIN * →k1 表示每一行的起始位置(偏移量offset) * @param VALUEIN * →v1 表示每一行的文本内容 * @param KEYOUT * →k2 表示每一行中的每个单词 * @param VALUEOUT * →v2 表示每一行中的每个单词的出现次数,固定值为1 */ public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException { String[] spilted = value.toString().split(" "); for (String word : spilted) { context.write(new Text(word), new LongWritable(1L)); } }; } /** * @author Edison Chou * @version 1.0 * @param KEYIN * →k2 表示每一行中的每个单词 * @param VALUEIN * →v2 表示每一行中的每个单词的出现次数,固定值为1 * @param KEYOUT * →k3 表示每一行中的每个单词 * @param VALUEOUT * →v3 表示每一行中的每个单词的出现次数之和 */ public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { protected void reduce(Text key, java.lang.Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException { long count = 0L; for (LongWritable value : values) { count += value.get(); } context.write(key, new LongWritable(count)); }; } // 输入文件路径 public static final String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/words.txt"; // 输出文件路径 public static final String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/wordcount"; public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // 0.0:首先删除输出路径的已有生成文件 FileSystem fs = FileSystem.get(new URI(INPUT_PATH), conf); Path outPath = new Path(OUTPUT_PATH); if (fs.exists(outPath)) { fs.delete(outPath, true); } Job job = new Job(conf, "WordCount"); job.setJarByClass(MyWordCountJob.class); // 1.0:指定输入目录 FileInputFormat.setInputPaths(job, new Path(INPUT_PATH)); // 1.1:指定对输入数据进行格式化处理的类(可以省略) job.setInputFormatClass(TextInputFormat.class); // 1.2:指定自定义的Mapper类 job.setMapperClass(MyMapper.class); // 1.3:指定map输出的<K,V>类型(如果<k3,v3>的类型与<k2,v2>的类型一致则可以省略) job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 1.4:分区(可以省略) job.setPartitionerClass(HashPartitioner.class); // 1.5:设置要运行的Reducer的数量(可以省略) job.setNumReduceTasks(1); // 1.6:指定自定义的Reducer类 job.setReducerClass(MyReducer.class); // 1.7:指定reduce输出的<K,V>类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 1.8:指定输出目录 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); // 1.9:指定对输出数据进行格式化处理的类(可以省略) job.setOutputFormatClass(TextOutputFormat.class); // 2.0:提交作业 boolean success = job.waitForCompletion(true); if (success) { System.out.println("Success"); System.exit(0); } else { System.out.println("Failed"); System.exit(1); } } }
3.5 运行吧小DEMO
(1)调试查看控制台状态信息
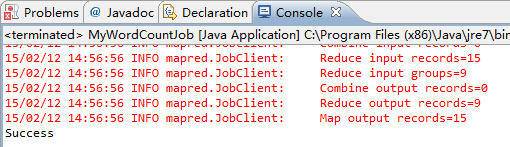
(2)通过Shell命令查看统计结果
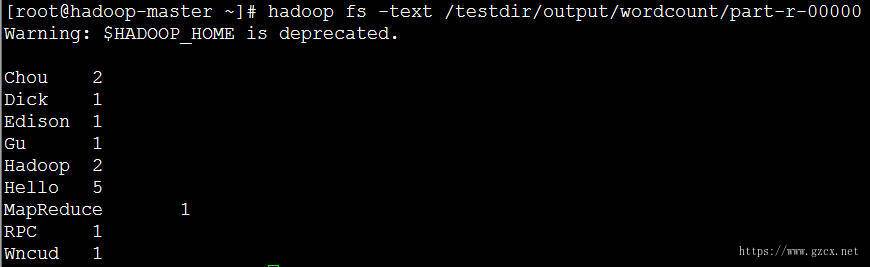
四、使用ToolRunner类改写WordCount
Hadoop有个ToolRunner类,它是个好东西,简单好用。无论在《Hadoop权威指南》还是Hadoop项目源码自带的example,都推荐使用ToolRunner。
4.1 最初的写法
下面我们看下src/example目录下WordCount.java文件,它的代码结构是这样的:
public class WordCount { // 略... public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); // 略... Job job = new Job(conf, "word count"); // 略... System.exit(job.waitForCompletion(true) ? 0 : 1); } }
WordCount.java中使用到了GenericOptionsParser这个类,它的作用是将命令行中参数自动设置到变量conf中。举个例子,比如我希望通过命令行设置reduce task数量,就这么写:
bin/hadoop jar MyJob.jar com.xxx.MyJobDriver -Dmapred.reduce.tasks=5
上面这样就可以了,不需要将其硬编码到java代码中,很轻松就可以将参数与代码分离开。
4.2 加入ToolRunner的写法
至此,我们还没有说到ToolRunner,上面的代码我们使用了GenericOptionsParser帮我们解析命令行参数,编写ToolRunner的程序员更懒,它将 GenericOptionsParser调用隐藏到自身run方法,被自动执行了,修改后的代码变成了这样:
public class WordCount extends Configured implements Tool { @Override public int run(String[] arg0) throws Exception { Job job = new Job(getConf(), "word count"); // 略... System.exit(job.waitForCompletion(true) ? 0 : 1); return 0; } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new WordCount(), args); System.exit(res); } }
看看这段代码上有什么不同:
(1)让WordCount继承Configured并实现Tool接口。
(2)重写Tool接口的run方法,run方法不是static类型,这很好。
(3)在WordCount中我们将通过getConf()获取Configuration对象。
可以看出,通过简单的几步,就可以实现代码与配置隔离、上传文件到DistributeCache等功能。修改MapReduce参数不需要修改java代码、打包、部署,提高工作效率。
4.3 重写WordCount程序
public class MyJob extends Configured implements Tool { public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException { ...... } }; } public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { protected void reduce(Text key, java.lang.Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException { ...... }; } // 输入文件路径 public static final String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/words.txt"; // 输出文件路径 public static final String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/wordcount"; @Override public int run(String[] args) throws Exception { // 首先删除输出路径的已有生成文件 FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf()); Path outPath = new Path(OUTPUT_PATH); if (fs.exists(outPath)) { fs.delete(outPath, true); } Job job = new Job(getConf(), "WordCount"); // 设置输入目录 FileInputFormat.setInputPaths(job, new Path(INPUT_PATH)); // 设置自定义Mapper job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 设置自定义Reducer job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 设置输出目录 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); System.exit(job.waitForCompletion(true) ? 0 : 1); return 0; } public static void main(String[] args) { Configuration conf = new Configuration(); try { int res = ToolRunner.run(conf, new MyJob(), args); System.exit(res); } catch (Exception e) { e.printStackTrace(); } } }
参考资料
(1)王路情,《Hadoop之MapReduce》:http://blog.csdn.net/wangloveall/article/details/21407531
(2)Suddenly,《Hadoop日记之MapReduce》:http://www.cnblogs.com/sunddenly/p/3985386.html
(3)伯乐在线,《我是如何向老婆解释MapReduce的》:http://blog.jobbole.com/1321/
(4)codingwu,《MapReduce原理与设计思想》:http://www.cnblogs.com/archimedes/p/mapreduce-principle.html
(5)codingwu,《MapReduce实例浅析》:http://www.cnblogs.com/archimedes/p/mapreduce-example-analysis.html
(6)挑灯看剑,《图解MapReduce原理和执行过程》:http://blog.csdn.net/michael_kong_nju/article/details/23826979
(7)万川梅、谢正兰,《Hadoop应用开发实战详解(修订版)》:http://item.jd.com/11508248.html
(8)张月,《Hadoop MapReduce开发最佳实践》:http://www.infoq.com/cn/articles/MapReduce-Best-Practice-1












